
Prêmio Innovare anuncia os projetos vencedores de sua 20ª edição

12 de dezembro de 2023.
O Prêmio Innovare anunciou as práticas vencedoras e homenageadas de sua 20ª edição nesta terça-feira (12/12), no Salão Branco do Supremo Tribunal Federal, em Brasília.
O Innovare teve nove práticas premiadas e seis receberam menção honrosa em um universo de 774 escolhidas para participar do prêmio neste ano. As iniciativas falam de temas como atendimento jurídico a povos indígenas e à população de rua; educação em cultura afrobrasileira; apoio a vítimas de violência doméstica; economia do cuidado; e educação na Polícia Federal.

Ministro Alexandre de Moraes posa ao lado das vencedoras na Categoria “Defensoria Pública”
Entre as homenageadas, estão práticas que promovem redes de apoio a pessoas com problemas de saúde mental e a pessoas privadas de liberdade; educação sobre abuso sexual para crianças e professores; missão de observação eleitoral; e um projeto que disponibiliza o acesso a gravações dos interrogatórios feitos pelo Tribunal de Justiça Militar nos tempos da ditadura.
Todas elas vão compor, a partir de janeiro, o Banco de Práticas do Innovare, que tem 9.372 iniciativas cadastradas desde 2004, quando o prêmio foi lançado.
O prêmio destaca as boas iniciativas da área jurídica, idealizadas e colocadas em prática por advogados, defensores, promotores, magistrados e por profissionais interessados em aprimorar a Justiça brasileira, facilitando o acesso da população ao atendimento.
Conheça as práticas premiadas no Prêmio Innovare 2023:
Prêmio Márcio Thomaz Bastos
Poranga Pesika — Por uma Defensoria Intercultural
 Defensoria Pública do Amazonas
Defensoria Pública do Amazonas
Local: São Gabriel da Cachoeira (AM)
Autores: Isabela do Amaral Sales, Ronaldo Antonio Rafael, Daniele Rosana Prado Arantes, Wildenise Melgueiro das Chagas e Álvaro Socot
Criada da cidade de São Gabriel da Cachoeira, onde 80% da população se autodeclara indígena, a prática possibilita que o atendimento seja feito com apoio de intérpretes e colaboradores falantes das principais línguas indígenas da região. No Alto Rio Negro, noroeste amazônico, vivem mais de 23 povos indígenas de diferentes etnias que falam mais de 20 línguas, três das quais reconhecidas oficialmente: Tukano, Baniwa e Nheengatu (clique aqui para saber mais).
Em Defesa da Democracia e da Justiça no Brasil
Comissão Arns
Local: São Paulo
Autores: André Feitosa Alcântara e José Carlos Dias
A Comissão Arns é uma organização da sociedade civil formada em 2019 por juristas, intelectuais, jornalistas, ativistas e voluntários na defesa dos direitos humanos. Participa intensamente de articulações internacionais para denunciar atos autoritários do governo brasileiro e garantir a democracia com o respeito às instituições do sistema de justiça e as eleições. O grupo atua de forma voluntária e suprapartidária, em rede com milhares de defensores de direitos humanos de todo o país. É uma das articuladoras do Pacto Pela Vida e Pelo Brasil, ao lado de CNBB, OAB, ABI, SBPC e ABC (clique aquipara saber mais).
Categoria CNJ — LGBTFobia não é opinião, é crime!
Tribunal de Justiça do Maranhão (TJ-MA)
Local: São Luiz
Autores: Marco Adriano Ramos Fonseca, em coautoria com Elaile Silva Carvalho, Adriana Da Silva Chaves e os membros do comitê Luciano Lopes Vilar, Marcelo Ricardo Cordeiro Cardoso, Joseane Cantanhede dos Santos e Joelma Regina do Nascimento
A prática, implantada em 2020, promove a articulação de parceiros institucionais para criar e disseminar campanha para combater a LGBTFobia, mediante estratégias de sensibilização e conscientização da sociedade. Além disso, a prática também promove a otimização do acesso do público LGBTQIA+ à Justiça. A campanha hoje atende a todo o estado do Maranhão, distribuída em 107 comarcas e 217 municípios (clique aqui para saber mais).
Categoria Tribunal — Programa POP Rua Justiça Federal 3ª Região
Tribunal Regional Federal da 3ª Região
Local: São Paulo
Autora: Marisa Claudia Gonçalves Cucio
O Programa POP Rua JUD assegura às pessoas em situação de rua amplo acesso à Justiça e a demais serviços públicos relacionados, mediante parcerias com órgãos públicos e instituições privadas de cunho social. Além do atendimento assistencial e de saúde, há expedição de documentos e atendimento jurídico por instituições parceiras, além da garantia de acesso à Justiça para ações e procedimentos, principalmente assistenciais e previdenciários. Atualmente o programa atende também a zonas periféricas e rurais de difícil acesso (clique aqui para saber mais).
Categoria Juiz — Somos Marias
Local: Peruíbe (SP)
Autores: Danielle Camara Takahashi Cosentino Grandinetti, em parceria com Orlando Brunetti Barchini e Santos e a ONG Humanitas360
A prática promove um atendimento menos burocrático para mulheres vítimas de violência doméstica, em um ambiente em separado, onde funciona o cartório da vara (anexo ao Fórum de Peruíbe). Lá, as vítimas podem receber atendimento jurídico e psicológico, fazer cursos e confeccionar artesanato para vender e ter alguma renda. A prática também promove a conscientização dos agressores, que passam por um curso para aprenderem a trabalhar suas emoções (clique aqui para saber mais).
Categoria Ministério Público — Projeto Ilé-Iwé
Ministério Público do Estado de Sergipe
Local: Aracaju
Autor: Luis Fausto Dias de Valois Santos
Oferta formação continuada a coordenadores pedagógicos e professores das escolas das redes municipais de ensino de Aracaju, São Cristóvão e Nossa Senhora do Socorro para estimular a cultura negra nas escolas e promover o debate sobre movimentos negos e das comunidades de terreiro. O projeto também abrange escolas da rede estadual de Sergipe e visa a integrar o sistema de Justiça com o sistema público de ensino, trazendo para essas instituições arte, história, dança folclore, orquestras de atabaques, maracatu, culinária e outros diversos elementos que mostram a contribuição do povo negro na cultura, arte e sociedade brasileiras. A palavra Ilé-Iwé significa “escola” em iorubá (clique aqui para saber mais).
Categoria Defensoria Pública — Economia do Cuidado: A consideração do trabalho não remunerado para fins de remição de pena
Defensoria Pública do Estado do Paraná
Local: Guarapuava (PR)
Autoras: Mariela Reis Bueno, Nilva Maria Rufatto Sell
Promove o reconhecimento do trabalho doméstico e materno, contra a invisibilização das funções historicamente atribuídas às mulheres. A possibilidade de remição de pena pelo trabalho doméstico, em especial para as mulheres monitoradas, poderá reduzir em até 30% o tempo de cumprimento de pena remanescente, além de contribuir com a redução de custos para o Estado (com os equipamentos, pessoas para sua operacionalização, eventual custo com regressão de regime para o sistema fechado, entre outros) (clique aqui para saber mais).
Categoria Advocacia — Acesso à Justiça para Povos Indígenas que Vivem em Isolamento
Local: Santarém (PA)
Autoras: Carolina Ribeiro Santana, Patricia Borba, Kri Guajajara (Maria Judite Baleeiro) e Catarina Ramos
A prática “Acesso à Justiça para povos indígenas que vivem em isolamento” é um braço do Observatório dos Direitos Humanos dos Povos Indígenas Isolados e de Recente Contato (OPI). O Observatório é formado por um grupo de indígenas e indigenistas que, juntos, buscam garantir que os direitos dos povos indígenas que vivem em isolamento e em recente contato sejam mantidos e, mais que isso, efetivados. A iniciativa de instituir uma estratégia jurídica no Opi foi de Bruno Pereira, assassinado em junho de 2022, com Dom Phillips, no Vale do Javari (AM). Desde que Bruno as convidou, a equipe passou a atuar em prol dos direitos dos indígenas que fazem parte dessa minoria extremamente vulnerável em razão de sua opção pelo isolamento e, em virtude de seus usos, costumes e tradições (clique aqui para saber mais).
Categoria Justiça e Cidadania — Especialização em Segurança Pública Contemporânea
Polícia Federal
Local: Brasília
Autores: Luciana do Amaral Alonso Martins, Rodrigo de Souza Carvalho, Márcio Alberto Gomes Silva e Gilson Matilde Diana
Tem como objetivo capacitar policiais federais aptos à progressão para Classe Especial acerca de temas contemporâneos que norteiam o trabalho policial e seus impactos em questões democráticas e sociais. Visa a atender as complexidades da prevenção e do enfrentamento ao crime organizado, corrupção, terrorismo e demais crimes graves, utilizando tecnologia, métodos e processos aperfeiçoados (clique aqui para saber mais).
Leia a matéria na fonte: https://www.conjur.com.br/2023-dez-12/premio-innovare-anuncia-vencedores-e-homenageados-da-20a-edicao/
Puxando a rede do IPOL:
. G1. assista a matéria sobre o prêmio Innovare 23. destaque aos 01min30 com o programa da Defensoria Pública da União (DPU-AM) que garante tradutores indígenas no atendimento e aos 03min15m um projeto que combate o racismo nas escolas em Sergipe.
https://g1.globo.com/jornal-nacional/playlist/jornal-nacional-ultimos-videos.ghtml#video-12190309-id
. DPAM ganha Prêmio Destaque por trabalho com indígenas do Alto Rio Negro – 19/10/2023
. DEFENSORIA DO AM VENCE PRÊMIO MÁRCIO TOMÁZ BASTOS, CATEGORIA DESTAQUE DO INNOVARE
. DEFENSORIA CONQUISTA PRÊMIO INNOVARE 2023 COM PROJETO QUE UTILIZA INTÉRPRETES INDÍGENAS NO ATENDIMENTO
. “CARTÓRIOS DÃO VISIBILIDADE DOCUMENTAL A PESSOAS QUE NÃO EXISTEM FORMALMENTE”, AFIRMA DEFENSORA PÚBLICA
. POLO DO ALTO RIO NEGRO COMEMORA A MARCA DE 8,6 MIL ATENDIMENTOS NA REGIÃO
. Capítulo 13 – MANUAL DE ATENDIMENTO JURÍDICO A MIGRANTES E REFUGIADOS MIGRANTES INDÍGENAS: PRINCIPAIS DEMANDAS, PARTICULARIDADES E DIFICULDADES
https://direitoshumanos.dpu.def.br/wp-content/uploads/2022/05/Manual_CapÃ_tulo-13_compressed.pdf
Ensino indígena pós-covid – Que os governantes olhe para educação indígena, a realidade é alarmante. Por Ariene Susui – Agência Amazônia Real
O ano era 2020 e o mundo já enfrentava o caos da pandemia de Covid-19. Um dos maiores desafios globais foi o de preservar o ensino, mesmo que à distância. Nas comunidades indígenas, onde lideranças morreram sem socorro médico, a educação foi deixada de lado pelas autoridades. Sem recursos ou condições tecnológicas, muitas aulas deixaram de ser ministradas. As escolas não tinham acesso à internet e muitas estavam em estado precário. Para produzir um retrato educacional nas aldeias, a reportagem ouviu professoras e lideranças indígenas de quatro Estados da Amazônia brasileira. Três anos se passaram e a pandemia ainda se faz presente. Não mais pelo vírus letal, mas pela flagrante carência de infraestrutura e por problemas de saúde mental que os alunos carregam até hoje.

Escola Estadual Indígena Tobias Barreto, em Roraima (Foto Wei Tenente)
Boa Vista (RR) – A ferida, na verdade, já estava aberta: a pandemia do novo coronavírus apenas inflamou os persistentes problemas da educação escolar indígena. Os alunos apresentam, hoje, deficiência de leitura e escrita, o processo de alfabetização foi fragilizado e os professores adoeceram. Sobram relatos de depressão. “Vai demorar muito tempo, coisa de 8 a 10 anos, e ainda assim não iremos conseguir recuperar o que a pandemia causou na educação e nas comunidades indígenas”, arrisca Rosivânia Demétrio, que até setembro era coordenadora da Organização dos Professores Indígenas de Roraima (Opirr).
Durante os longos meses de pandemia, não houve assistência por parte dos governos em relação à questão psicológica do aluno, do professor e da própria educação indígena. Mas não só. A precariedade das escolas indígenas, a falta de estrutura, onde faltam materiais, prédios adequados e merenda de qualidade, foram ainda mais expostos. E tudo continua da mesma forma.
No final de 2020, bem no meio da pandemia, estive na comunidade Catual, na Terra Indígena (TI) Trombetas Mapuera, no município de Caroebe (RR). A convite da comunidade, decidi me deslocar até lá por conta própria. Para chegar até o povo Wai Wai, foi uma longa viagem de dois dias, incluindo ônibus, um carro fretado e três horas de barco. Ali, presenciei as dificuldades de uma das centenas de escolas de difícil acesso da Amazônia. Ninguém chega até esse território se não for pela via fluvial. Os relatos ouvidos naquela viagem acabaram me acompanhando por todos esses anos.
Não havia aulas. As lideranças me levaram até uma sala de aula, que estava vazia de alunos, por conta da pandemia. Perguntei se outras escolas da região também estavam nessas condições e me confirmaram que enfrentavam a mesma realidade. A situação desde aquele ano não mudou, apesar dos pedidos para a construção de um prédio novo. A escola funcionava em uma estrutura que a própria comunidade criou.
O drama do povo Wai-Wai foi o ponto de partida que me motivou a propor essa investigação sobre a educação indígena no pós-pandemia para a Associação de Jornalistas de Educação (Jeduca). Com a ajuda providencial de comunicadores indígenas da rede da Coordenação das Organizações Indígenas da Amazônia Brasileira (Coiab), Rede Wayuri (da Federação das Organizações Indígenas do Rio Negro) e Wakywai (do Conselho Indígena de Roraima), pude viajar até Roraima e ouvir relatos de lideranças e também professores de outras localidades e Estados.
A educação indígena de Roraima está entre as piores do Brasil. De acordo com os dados da Secretaria de Educação e Desporto do Estado (Seed), há cerca de 2.300 professores indígenas entre os efetivos, da União e do quadro temporário. Já o Censo Escolar da Educação Básica de 2021 indica que havia 247 escolas indígenas. Porém, mais da metade delas não possuem infraestrutura adequada para funcionamento, é o que apontam os dados do Censo Escolar de 2021.
“A maior dificuldade das escolas indígenas é a estrutura que está muito precária. Há escolas que nunca foram construídas e outras que nunca tiveram reforma”, afirma Rosivânia Demétrio, da Opirr. Diante da deficiência ou omissão do poder público, a própria comunidade constrói as escolas. Mas faltam a elas os demais equipamentos – cadeiras, quadros, material didático – e equipe de funcionários, como merendeira, vigia e zelador.

Aula em um barracão

“Os próprios indígenas constroem um barracão bem grande e temos relatos que tem alunos que sentam em bancos improvisados de madeira. Quando chove, acaba molhando as salas de aulas”, descreve Rosivânia. A própria Opirr denunciou o caso junto ao Ministério Público Federal (MPF), mas sem nenhum resultado. “Algumas escolas estão sendo maquiadas, uma pintura ali é só. A maioria delas, principalmente as de difícil acesso, nem isso estão sendo.”
A reportagem procurou o MPF de Roraima para saber se adotou alguma providência em relação à denúncia da coordenadora, por meio da Lei de Acesso à Informação. Mas até a publicação desta reportagem não obteve respostas.
Dário Yanomami, vice-presidente da Hutukara Associação Yanomami (HAY), relata à reportagem sobre o total abandono das escolas indígenas em seu território, já intensamente pressionada pela crise sanitária gerada pelas invasões de garimpeiros. No período pandêmico, como estratégia para escapar da Covid-19, muitos Yanomami fugiram para dentro da floresta, ficando por lá até três meses. Esse foi um dos motivos para a paralisação das aulas, mas que não deveria servir de desculpa para que as unidades de ensino dentro do território continuassem esquecidas – na época e agora.
Na TI Yanomami, há 21 escolas estaduais em funcionamento, cerca de 80 educadores e 1.478 alunos, de acordo com a Seed de Roraima. São números que impressionam, e indicariam a atenção estadual para a educação indígena. Mas isso está longe de ser verdade, afirma Dário Yanomami. “Durante os últimos 15 anos, as escolas Yanomami não tiveram nenhum apoio do governo, não teve sequer uma construção de escola. Os Yanomami fazem suas próprias salas de ensino com palhas e madeiras artesanais.”
O líder indígena menciona que a única coisa que o governo estadual apoiou foi o processo seletivo para professores indígenas. Porém, esses docentes não possuem uma estrutura mínima para oferecer ensino de qualidade. Dário relata que quem compra os materiais, muitas vezes, são os próprios professores – fato que se repete em outras escolas indígenas de Roraima.
Como as escolas estão localizadas em áreas de difícil acesso, só é possível recorrer ao avião para entrar e sair das aldeias Yanomami. Quando querem sacar o salário em uma agência bancária, os professores precisam pedir carona para a Secretaria Especial da Saúde Indígena (Sesai), a própria organização Hutukara ou o Instituto Socioambiental. Já houve casos em que eles se juntaram para pagar a hora de voo de um avião, que custa em média 13.850 reais.
Joênia Wapichana, hoje presidenta da Fundação Nacional para os Povos Indígenas (Funai), afirma que durante seu mandato como deputada federal (2018-2022) destinou 49 milhões de reais em emendas parlamentares para estruturar e apoiar a educação indígena em Roraima. Mas, para isso acontecer, era preciso que o governo do Estado atuasse em conjunto. Segundo Rosivânia Demétrio, parte desses recursos ainda não foi aplicada nas escolas que estão dentro do planejamento para estruturação.
Procurados, a Seed e a chefia de gabinete do governo de Roraima não responderam à reportagem. Deixam, assim, de prestar esclarecimentos sobre o destino das emendas e também de responder por que as escolas indígenas não possuem salas de aulas adequadas, kits escolares, merenda de qualidade.
Defasagem persiste

Com a Constituição Federal de 1988, os povos indígenas conquistaram o direito de ter a educação de acordo com suas realidades e dentro de seus territórios. Mas só isso não basta. A realidade dentro das escolas indígenas é vergonhosa, desabafa a professora Aldira Akay, do povo Munduruku, da TI Sawary Ba’ay, em Itaituba (PA).
Nessa TI, nenhuma escola foi construída pelo poder público e a história se repete, fazendo com que a distância entre Roraima e Pará seja apenas geográfica. A Escola Sawary Ba’ay, que possui 43 alunos, foi erguida pela própria aldeia. “Já pressionamos, disseram que iam fazer, mas até agora nem mesmo iniciou”, diz Aldira Akay.
A professora relata que, durante a pandemia, os indígenas foram totalmente abandonados pelo governo estadual e federal. Apenas as organizações não governamentais prestaram alguma ajuda. “Quando a gente ficou doente, nossas crianças ficaram doentes, nós mesmos tivemos que fazer remédio tradicional.” Mas agora, pós-Covid, restaram os problemas de saúde mental que afetam muito as crianças indígenas. Mas não há psicólogos.
Entramos em contato com a Secretaria de Educação do município de Itaituba. Até a publicação desta reportagem, foram feitas duas tentativas de contato e em nenhuma delas houve resposta.
As marcas da Covid-19
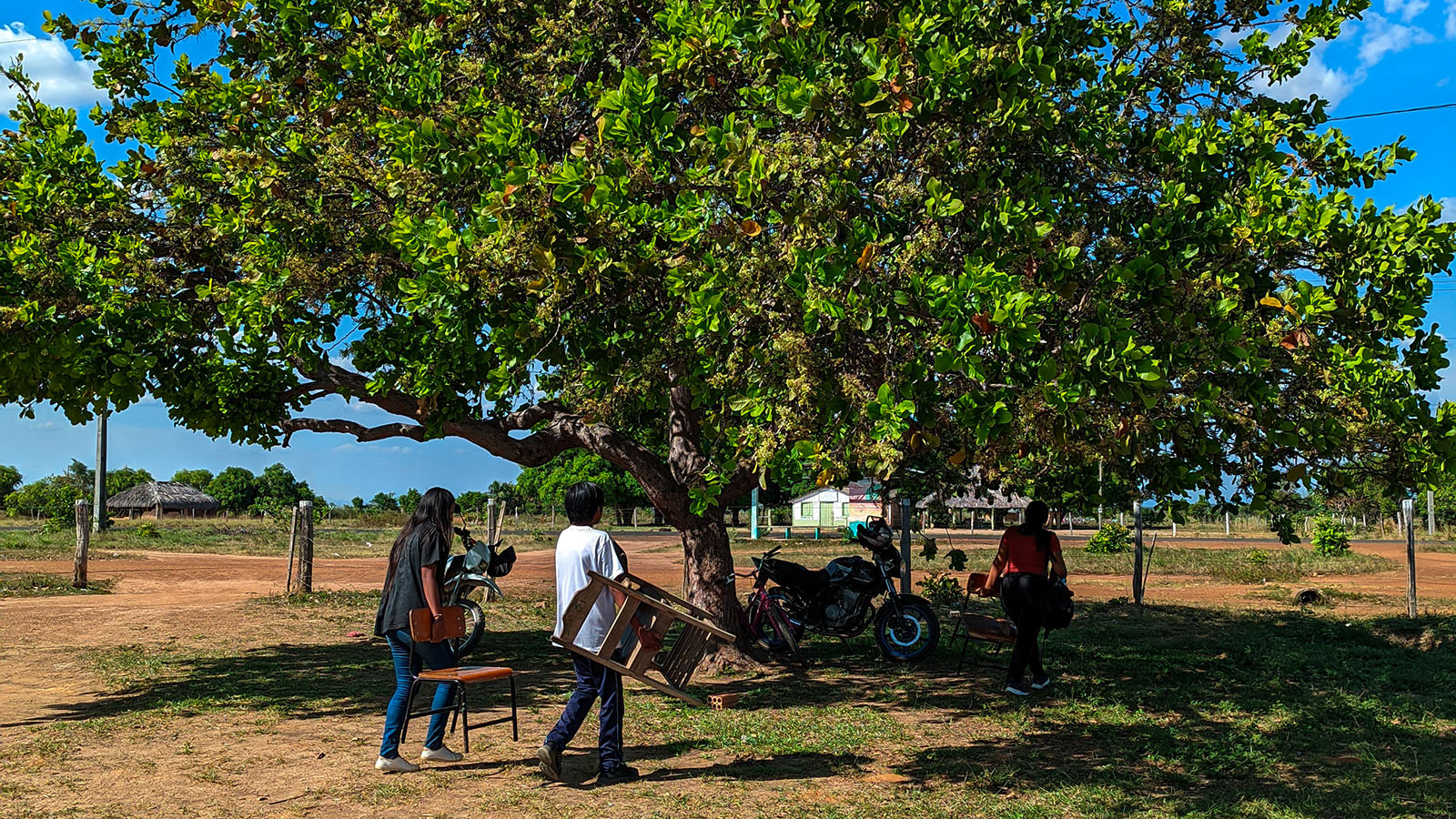
Alunos da Escola Estadual Indígena Tobias Barreto, no município de Amajari, em Roraima carregam cadeiras para aula embaixo de árvore (Foto WEI Tenente).
A psicóloga Iterniza Macuxi atendeu a inúmeros alunos indígenas em Roraima no período pandêmico. Ela pontua que uma das maiores violências que a pandemia causou foi o sofrimento dos indígenas que não conseguiram enterrar os parentes no seu território. “A falta do ritual de passagem (velório) afetou muito a vida dos povos indígenas e, consequentemente, a escola. O sentimento de vazio, de tristeza, de ter alguém partindo, mas de não poder fazer o ritual, que na cultura indígena é importante, foi algo que deixou uma lacuna aberta e que hoje tem pessoas que ainda estão tendo essa dificuldade”, explica.
Iterniza pontua ainda que hoje se depara com relatos de vários adolescentes que apresentam crise de ansiedade, tentativa de suicídio e automutilação. “Quando começaram a retornar às aulas presenciais, os alunos ficaram com muito medo de voltar à escola. Vários alunos e professores foram diagnosticados com síndrome do pânico”, relata a psicóloga, que hoje atua no Distrito Sanitário Especial Indígena (Dsei) Leste, em Roraima.
Professores podem solicitar atendimento psicológico diretamente na Seed de Roraima. Mas Rosivânia Demétrio, da Opirr, menciona que o modelo adotado não consegue atender à realidade dos professores indígenas, por precisarem sair de suas comunidades que muitas das vezes são distantes da capital.
“Para os docentes indígenas terem atendimento, eles têm que vir aqui em Boa Vista agendar atendimento. Agora você imagina, um professor que mora em uma região distante, a mais de 300 quilômetros de distância? Em época de chuva, você não consegue atravessar. Você vem e volta para marcar agendamento, isso já é um gasto, e aí vai ter que retornar naquele dia que o psicólogo marcou. E às vezes você nem é atendido”, explica Rosivânia.
O governo estadual de Roraima, procurado, não explicou o motivo de não constar no planejamento pós-pandemia atendimento de psicólogos para as escolas indígenas.
O problema da evasão


Transporte da merenda para as escolas indígenas em São Gabriel da Cachoeira, no Amazonas e o material didático armazenado de forma inadequada (Fotos: Juliana Albuquerque do povo Baré/ Rede Wayuri).
No extremo oeste do Amazonas, a 850 quilômetros de Manaus, São Gabriel da Cachoeira é o município com maior diversidade étnica do país, com 23 povos indígenas. E é de lá que chegam informações alarmantes. De acordo com Melvino Fontes Baniwa, coordenador do departamento de Educação da Federação das Organizações Indígenas do Rio Negro (Foirn), a evasão de alunos indígenas é uma realidade após a pandemia. Por conta do deslocamento que muitos alunos tinham de fazer para ir às escolas, muitos acabaram se evadindo, mudando de endereço e de comunidade. Mas para o coordenador o problema vai além.
“Na verdade, são três pontos: A falta de transporte escolar – aqui a grande maioria vem de barco –, de material didático e de merenda. Todos esses aspectos fizeram com que os alunos desistissem”, destaca o coordenador. “As escolas estão abandonadas, os professores e os alunos não têm material, nem mesmo caneta, lápis ou caderno. Tudo isso acabou influenciando. Aí quando a pandemia chegou, completou essa defasagem.”
No município amazonense, há 235 escolas municipais indígenas e 12 escolas indígenas do Estado. Melvino relata que, na falta do transporte escolar, os alunos usam o transporte familiar – que não é adequado para ir à escola. “Tem alunos que vão, por exemplo, a remo. A gente tem que pensar no bem-estar e no bem-viver dos povos indígenas, principalmente das crianças, que hoje estão correndo risco”, critica Melvino.
Entramos em contato com a Secretaria de Educação de São Gabriel da Cachoeira, mas o órgão não respondeu.
Falhas no ensino superior

Se a educação básica (do ensino infantil ao médio) vai mal, a de nível superior poderia representar uma luz no fim do túnel. Com mais indígenas se formando em diferentes profissões, melhor será o atendimento das necessidades desses povos. Esse movimento já foi iniciado, porém segue a passos lentos. De acordo com dados do Instituto Nacional de Estudos e Pesquisas Educacionais (Inep), dos 8,9 milhões de estudantes na educação superior em 2022, 46.252 são indígenas, o que equivale a 0,5%. Mais da metade deles está na Amazônia. No entanto, a entrada nas faculdades e universidades não é o principal desafio a ser superado.
A liderança e estudante de Licenciatura Intercultural Indígena, Luene Karipuna, mora no Município de Oiapoque, no Amapá, está na fase final da graduação na Universidade Federal do Amapá (Unifap), e detalha como foi o caminho até chegar a esse estágio da formação.
“Comecei a morar no Município de Oiapoque em 2019, um ano antes da pandemia estourar. Foi na cidade que entendi que não basta dar oportunidade de entrar na universidade. É preciso que haja política para que o aluno permaneça nela”, inicia Luene Karipuna. Ela lembra que observou que muitos colegas só chamavam os alunos indígenas para expor artesanato. “Todas as vezes que a gente tentou entrar nos espaços de discussão científica, fomos tratados com preconceito, com olhares estranhos. Acredito que isso tem sido um dos aspectos mais importantes dentro da universidade, o de desconstruir esse tipo de narrativa sobre nós.”
A futura professora conta que, se for levar em consideração a vida na cidade, a bolsa permanência, que até 2022 era de 900 reais, não cobria nem a metade dos custos da vida estudantil. Só para visitar sua aldeia, ela gastava em média 400 reais. Ou seja, apenas com a bolsa não conseguia ir para o seu território com frequência.
“Para chegar na minha comunidade, a gente vai via terrestre até um ponto que é a entrada da Terra Indígena Uaçá. E aí a gente pega mais ou menos 20, 30 minutos de voadeira para chegar na minha aldeia. A gente paga transporte de frete, temos que comprar combustível para descer o rio até chegar”, explica.
A liderança menciona que, na pandemia, muitos indígenas voltaram para as aldeias. Para não perder aulas, tentaram construir uma possibilidade de ensino remoto. Mas isso não funcionou para todo mundo, porque muitos dos seus colegas não tinham acesso à internet. O resultado foi a evasão de alunos, que foram para suas aldeias e não voltaram mais para os livros. Quem continuou ficou com o curso defasado.
“Nós atrasamos dois anos. Então já vão mais para seis ou sete anos que a gente está tentando concluir o nosso curso. Não teve assistência da universidade, a não ser alguns professores que se doaram mesmo para trabalhar com a gente. Foi um descaso, muitos alunos ficaram doentes psicologicamente”, relata a estudante.

A acadêmica ressalta ainda que a universidade não é um espaço preparado para receber alunos indígenas. “Estamos em 2023 e o pensamento esbranquiçado ainda continua sendo a base de ensino para alunos indígenas”, denuncia. Ela afirma que essa metodologia é um segundo obstáculo a ser enfrentado, já que o primeiro é a inexistência de uma política que segure o aluno na instituição.
Procuramos a Unifap para entender o motivo de não conseguirem dar assistência aos alunos indígenas no câmpus do Oiapoque durante o período de pandemia, e se hoje há alguma política para que esses alunos consigam concluir o curso. Por meio da Assessoria de Comunicação da universidade, recebemos a resposta de que iam verificar a demanda, mas até o fechamento desta reportagem não houve resposta.
Falta de comunicação

A língua materna é outro ponto sensível no ensino superior indígena. Com a possibilidade de entrada na graduação, muitos indígenas saem de suas aldeias e, por não terem o domínio da língua portuguesa, acabam correndo risco de serem explorados. É o que Luene relata, em detalhes, sobre o que ocorreu com uma colega:
“Tinha um estudante indígena na Unifap muito caladinha. Naquela época, em 2019, todo mundo fazia vaquinha para poder lanchar, ainda não tínhamos bolsa-permanência. Certo dia, essa estudante desmaiou no corredor da sala porque não tinha o que comer. Eu sentei do lado dela, que estava chorando muito. Estava super fraquinha, já tinha três dias que não comia, só café da manhã. Ela me disse que morava de aluguel com a irmã num quarto bem pequenininho, e a dona daquele lugar cobrava 600 reais de cada uma delas. Então, elas preferiam não ter o que comer e ter onde dormir. Ainda dividiam o dinheiro dos artesanatos para sustentar os filhos. Elas estavam a ponto de desistir do curso. Não só elas, mas outros que não falam bem português e querem acessar a universidade têm esse grande obstáculo.”
Do Estado do Amazonas, Estélio Munduruku é estudante da pós-graduação em Geografia na Universidade Federal de Rondônia. Em sua caminhada acadêmica, ele menciona os desafios à saúde mental. “Nossa principal dificuldade é a assistência psicológica, pois no início é um baque bem difícil para quem vem das aldeias. Eu vim do Kwatá-Laranjal, município de Borba. Isso se dá porque a gente tem um ensino diferente na educação básica. Como a educação superior é muito exigente, requer muita produção. A gente acaba com a mente sugada, fora as questões socioeconômicas e culturais que a gente tem”, pontua Estélio, que hoje está finalizando a pós-graduação.
Educação específica e diferenciada
") Escola Indígena Sawrè Ba Ay, do povo Munduruku, da TI Sawary Ba’ay, em Itaituba ,no sudoeste do Pará que foi erguida pela própria comunidade (Foto: Aldira Akay).
Escola Indígena Sawrè Ba Ay, do povo Munduruku, da TI Sawary Ba’ay, em Itaituba ,no sudoeste do Pará que foi erguida pela própria comunidade (Foto: Aldira Akay).") Escola Indígena Sawrè Ba Ay, do povo Munduruku, da TI Sawary Ba’ay, em Itaituba ,no sudoeste do Pará que foi erguida pela própria comunidade (Foto: Aldira Akay).
Escola Indígena Sawrè Ba Ay, do povo Munduruku, da TI Sawary Ba’ay, em Itaituba ,no sudoeste do Pará que foi erguida pela própria comunidade (Foto: Aldira Akay).") Escola Indígena na comunidade de Catual na Terra Indígena Trombetas Mapuera, em Roraima foi feita pela própria comunidade de forma improvisada (Fotos Ariene Susui/ 2020).
Escola Indígena na comunidade de Catual na Terra Indígena Trombetas Mapuera, em Roraima foi feita pela própria comunidade de forma improvisada (Fotos Ariene Susui/ 2020).") Escola Indígena na comunidade de Catual na Terra Indígena Trombetas Mapuera, em Roraima foi feita pela própria comunidade de forma improvisada (Fotos Ariene Susui/ 2020).
Escola Indígena na comunidade de Catual na Terra Indígena Trombetas Mapuera, em Roraima foi feita pela própria comunidade de forma improvisada (Fotos Ariene Susui/ 2020).") Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).
Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).") Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).
Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).") Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).
Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).") Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).
Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).") Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).
Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).") Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).
Escola Estadual indígena Tobias Barreto, na comunidade Mangueira, distante 44 Km da Vila Brasil (sede do Município do Amajari, RR) (Foto: Wei Tenente).
Em dezembro de 1996, por meio da Lei nº 9.394, que estabelece as Diretrizes e Bases para a Educação Brasileira (LDB), outro importante passo foi dado com a determinação como norma legal do direito indígena à educação diferenciada. Mas apesar dos avanços, ainda há muito a ser feito. É o que destaca a liderança André Baniwa, escritor, político e um dos maiores ativistas da educação indígena.
“No nível da educação básica, é como se pintassem só a cara para dizer que é indígena, mas por dentro não tem nada de diferente. E mesmo que tenha o Conselho Nacional de Educação Escolar Indígena, o conselho não consegue avançar nesse sentido”, pontua André Baniwa.
Dário Kopenawa destaca que a educação específica só existe no papel, mas na prática o Estado insiste em não reconhecer os modos de vida dos povos indígenas. “A escola específica tem na escrita, mas na prática é diferente, precisamos o sistema educacional específico indígena nacional. Esse ensino diferenciado ainda não chegou, a escola indígena ainda é um pensamento do Estado. Esse ensino diferente não está funcionando na Terra Yanomami”, relata o líder indígena.
Há 15 anos, os Yanomami fizeram o Projeto Político-Pedagógico (PPP) para atendimento de escolas específicas. Nele, Dário e demais pessoas engajadas nesse processo colocaram no papel como deveria ser uma escola Yanomami, desde o pensamento do seu povo, o modo de viver, até o que ensinar para os alunos. “Temos o histórico dos animais, da floresta, da terra Yanomami, do nosso criador de Omama. Isso a gente quer ensinar para os nossos parentes, isso é ensino específico que ainda não é reconhecido pelo Estado”, cobra Dário.
Aldira Akay, do povo Munduruku, conta que o ensino da língua indígena foi reduzido de 100 horas para 10 horas por mês em sua escola, e pontua que isso acabou afastando as crianças da cultura indígena. “É um absurdo. Com essa perda, a gente vem percebendo que as nossas crianças estão cada vez mais perdendo a nossa língua, o cântico e outras histórias que estão envolvidas com a nossa cultura”, afirma Aldira, que dá aula para alunos do 1º e 2º anos do ensino fundamental.
Em relação à “pedagogia da floresta”, termo usado em muitos eventos de educação para se referir ao ensino indígena, o líder indígena e ativista da educação André Baniwa destaca que isso é mais uma tentativa dos não-indígenas de generalizar, que não deixa de excluir a especificidade da educação escolar indígena.
“Esse termo foi feito pelos pesquisadores não-indígenas. Essa pedagogia da floresta cai na mesma política da era dos missionários de querer criar uma língua única para todos os brasileiros. Eu acho muito perigoso quando se cria um conceito genérico que mata a especificidade das coisas. O que acho que deveria acontecer é conectar essas pedagogias. Seria muito mais importante do que criar um conceito que generalize tudo isso”, argumenta André Baniwa, líder da região do Alto Rio Negro.
* Pauta selecionada pelo 5º Edital de Jornalismo de Educação, da Jeduca e em parceria com a Fundação Itaú.

. Agência Amazônia Real, leia esta matéria diretamente na fonte e acesse outras importantes produções: https://amazoniareal.com.br/especiais/ensino-indigena-pos-covid/
Puxando a REDE IPOL:
. Instituto Socioambiental – ISA: Ariene Susui: com a caneta na mão e em espaços de poder! https://www.socioambiental.org/index.php/noticias-socioambientais/ariene-susui-com-caneta-na-mao-e-em-espacos-de-poder
. Siga Ariene Susui nas redes sociais:
https://twitter.com/ArieneSusui
https://www.instagram.com/ariene_susui/?hl=en
Um panorama multidisciplinar sobre a expansão do povo de língua tupi
O pesquisador Fabricio Ferraz Gerardi, https://twitter.com/fabricioicirbaf. Citado na postagem, Idiomas do tupi-guarani avançaram pela América do Sul em escala épica, link http://ipol.org.br/idiomas-do-tupi-guarani-avancaram-pela-america-do-sul-em-escala-epica/ repostou mensagem de outra pesquisadora da área, Tábita Hünemeier (twitter: @hunemeier_t) : “Check out our review of the complex dynamics surrounding the Tupi expansion, one of the greatest demographic movements in the late Holocene of America and arguably one of the least studied / Confira nossa análise da complexa dinâmica em torno da expansão Tupi, um dos maiores movimentos demográficos do final do Holoceno da América e, sem dúvida, um dos menos estudados.”
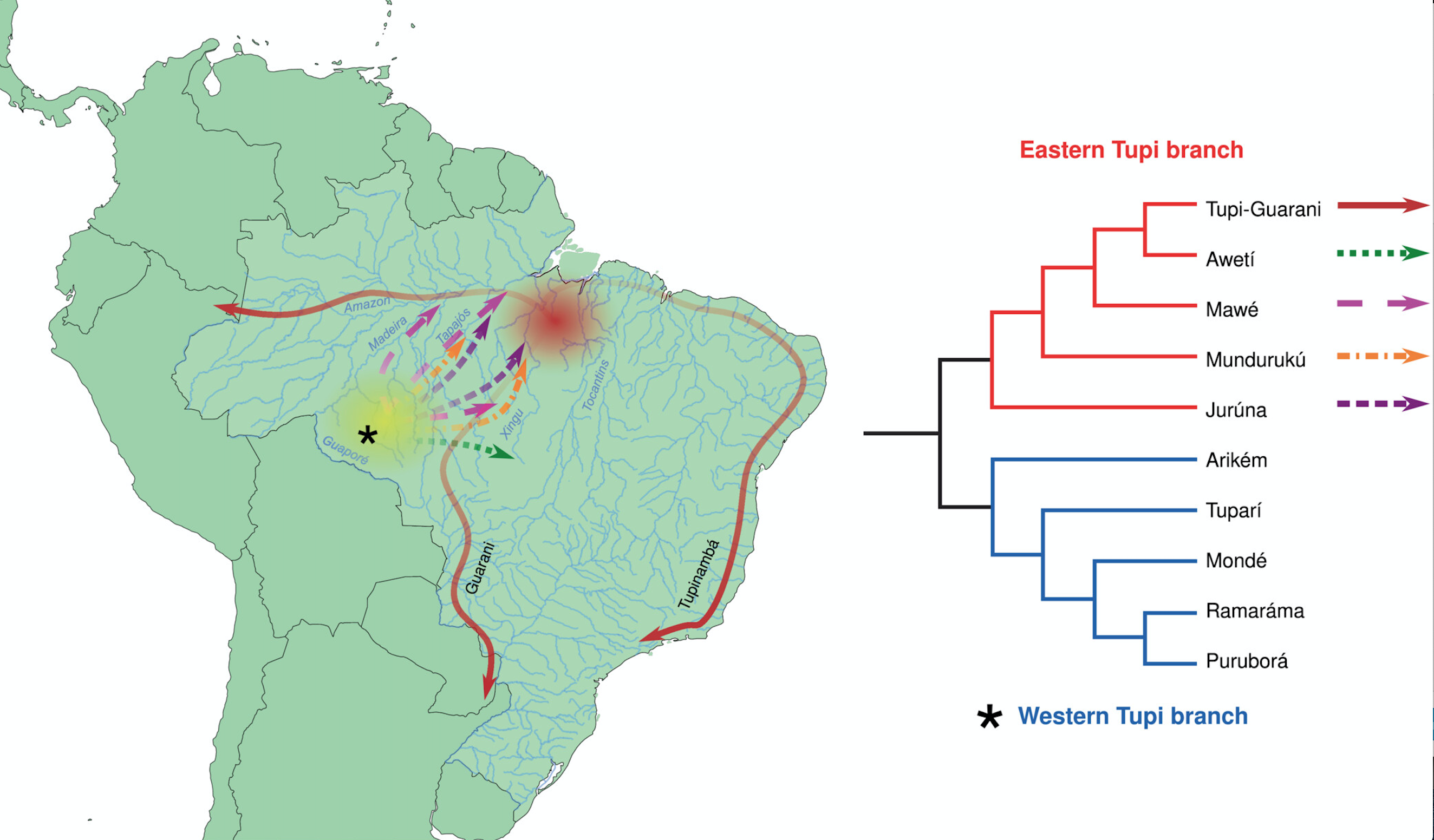
Expansão das subfamílias linguísticas Tupi. As áreas sombreadas em amarelo e vermelho, entre os rios Madeira e Guaporé, e os rios Xingu e Tocantins, representam os hipotéticos centros de origem dos Tupi e Tupi-Guarani, respectivamente.
Veja o resumo:
Um panorama multidisciplinar sobre a expansão do povo de língua tupi
A diversidade cultural e biológica dos grupos indígenas sul-americanos representa extremos da variabilidade humana, exibindo uma das maiores diversidades linguísticas, juntamente com uma variação genética intrapopulacional notavelmente baixa e uma diferenciação genética interpopulacional extremamente alta. Além disso, esta região assistiu a alguns dos acontecimentos demográficos mais dramáticos da história da humanidade, desencadeados pela colonização europeia das Américas. Como resultado deste processo, a distribuição das populações indígenas foi radicalmente alterada. Nesta revisão nos concentramos nos Tupi, a maior e mais difundida família linguística no leste da América do Sul. Acredita-se que os Tupi tenham se originado no sudoeste da Amazônia, de onde algumas de suas subfamílias se expandiram para outras partes da Amazônia e, no caso dos Tupi-Guarani, para além de suas fronteiras. Evidências recentes da arqueologia, linguística e genética alinham-se com o modelo de Expansão Tupi de José Brochado. Ele propôs que o desenvolvimento gradual dos sistemas agrícolas na Amazônia resultou no crescimento populacional e, eventualmente, na expansão territorial. Este modelo também suporta ramos separados da Expansão Tupi: Tupinambá (costa atlântica) e Guarani (sul e centro-oeste do Brasil). Embora sejam o grupo mais populoso da costa atlântica do Brasil, que foi o mais afetado pela colonização europeia, os Tupi ainda representam cerca de 20% da população indígena total do país. Finalmente, apesar de sua importância e de mais de um século de pesquisas sobre os Tupi e sua história de expansão, muitas questões-chave permanecem sem resposta, as quais tentamos resumir e explorar aqui.(tradução Google)
Acesse o artigo em https://onlinelibrary.wiley.com/doi/10.1002/ajpa.24876 em The Wiley Network
Ministra dos Povos Indígenas formaliza adesão do Brasil ao Instituto Iberoamericano de Línguas Indígenas (IIALI)
 Na última terça-feira, dia 21 de novembro de 2023, a ministra dos Povos Indígenas, Sonia Guajajara, assinou um ofício solicitando à Agência Brasileira de Cooperação (ABC) a adesão do Brasil ao Instituto Iberoamericano de Línguas Indígenas (IIbeLI). A formalização deste pedido visa preservar e revitalizar o patrimônio linguístico e cultural da América Latina e do Caribe, conforme aprovado na Cúpula Iberoamericana de fevereiro de 2022.
Na última terça-feira, dia 21 de novembro de 2023, a ministra dos Povos Indígenas, Sonia Guajajara, assinou um ofício solicitando à Agência Brasileira de Cooperação (ABC) a adesão do Brasil ao Instituto Iberoamericano de Línguas Indígenas (IIbeLI). A formalização deste pedido visa preservar e revitalizar o patrimônio linguístico e cultural da América Latina e do Caribe, conforme aprovado na Cúpula Iberoamericana de fevereiro de 2022.
A reunião da Organização Iberoamericana, agendada para o dia 27 de novembro, será palco para a ABC formalizar a adesão brasileira ao IIbeLI. Esta é uma iniciativa crucial para a preservação das cerca de 550 línguas na região, sendo um terço delas ameaçadas de extinção, é uma entrega concreta do Ministério dos Povos Indígenas durante sua liderança na Presidência Pro-tempore do Mercosul.
A adesão ao IIbeLI é estratégica para o reposicionamento do Brasil no cenário regional, destacando o protagonismo indígena. Durante a Reunião de Autoridades sobre Povos Indígenas do Mercosul (RAPIM), realizada em Brasília em 16 de novembro, a decisão brasileira já foi comunicada ao Vice-Presidente da Bolívia, David Choquehuanca, país sede do Instituto e um de seus maiores apoiadores.
Essa iniciativa ganha ainda mais relevância no contexto da Década Internacional das Línguas Indígenas da UNESCO, à medida que os países são chamados à ação para apoiar, promover e revitalizar as línguas indígenas. Além disso, a adesão fortalecerá a parceria com o FILAC (Fundo para o Desenvolvimento dos Povos Indígenas da América Latina e Caribe), possibilitando ações conjuntas em eventos como o Fórum Permanente sobre Questões Indígenas da ONU e a participação indígena na COP30 do Clima, em 2025, em Belém.
A medida alinha-se à intenção do presidente Lula de fortalecer a integração regional, especialmente no âmbito do Tratado de Cooperação Amazônica (TCA), considerando a concentração significativa das línguas indígenas na região.
Por fim, a adesão ao Instituto Iberamericano de Línguas Indígenas vem ao encontro das ações do Ministério dos Povos Indígenas que, por meio de seu Departamento de Línguas e Memórias Indígenas, chefiado pelo professor Eliel Benites. O Departamento apresentou este ano, no âmbito da RAPIM, o Plano de Ação para a Década Internacional das Línguas Indígenas no Brasil, o qual apresenta em detalhes os princípios, objetivos e, principalmente, as ações conduzidas à frente das políticas linguísticas no Brasil, tudo formulado com protagonismo indígena e intensos diálogos com instituições governamentais e não-governamentais especializadas na temática.
IIALI – O que é?
O Instituto Ibero-Americano de Línguas Indígenas é uma iniciativa para revitalizar as línguas indígenas

O Instituto Ibero-Americano de Línguas Indígenas (IIALI) tem sua origem em uma decisão da Cúpula Ibero-Americana de Chefes de Estado e de Governo, realizada em Montevidéu e Antígua-Guatemala em 2006 e 2018, respectivamente. Na XXVII Cúpula Ibero-Americana, realizada em Andorra em 2021, o instituto foi aprovado como uma iniciativa ibero-americana para enfrentar as ameaças às línguas indígenas, especialmente as ameaçadas de extinção, bem como para promover seu uso, revitalizar, fomentar e desenvolver as mesmas.
Esta iniciativa busca aumentar a consciência da situação das línguas indígenas e dos direitos culturais e linguísticos dos povos indígenas; promover a transmissão, uso, aprendizagem e revitalização das línguas indígenas; prestar assistência técnica na formulação e implementação de políticas linguísticas e culturais para os povos indígenas; e facilitar a tomada de decisão informada sobre o uso e vitalidade das línguas indígenas.
O instituto adota, entre outros, os princípios da Convenção 169 da OIT, a Declaração da ONU sobre os Direitos dos Povos Indígenas e a Declaração Los Pinos-Chapoltepek, adotada no evento de alto nível convocado pela UNESCO e pelo Governo do México em 2020, sob o lema “Nada sem nós”, que reconhece a importância das línguas indígenas para a coesão e inclusão social, direitos culturais, saúde e justiça.
A responsabilidade pela criação do Instituto foi confiada na XXVI Cúpula Ibero-Americana de Chefes de Estado e de Governo à Organização de Estados Ibero-Americanos para a Ciência e a Cultura (OEI), à Secretaria-Geral Ibero-Americana (SEGIB) e ao Fundo para o Desenvolvimento dos Povos Indígenas da América Latina e do Caribe (FILAC).

El IIALI tiene como objetivo general fomentar el uso, la conservación y el desarrollo de las lenguas indígenas habladas en América Latina y el Caribe, apoyando a las sociedades indígenas y a los Estados en el ejercicio de los derechos culturales y lingüísticos, objetivo que se logrará con la creación de un Instituto Iberoamericano de Lenguas Indígenas. Para ello, se busca:
- Concienciar sobre sobre la situación de las lenguas indígenas y los derechos culturales y lingüísticos de los Pueblos Indígenas, así como lograr:
- Que la sociedad global considere al IIALI como la piedra angular del Decenio Internacional de las Lenguas Indígenas en América Latina y el Caribe.
- Que la sociedad latinoamericana muestre mayor conocimiento y consciencia sobre la situación de vulnerabilidad y los riesgos que amenazan a los idiomas indígenas.
- Fomentar la transición, uso, aprendizaje y revitalización de los idiomas indígenas, a través de ello se busca:
- Que se retome la transmisión intergeneracional de los idiomas indígenas por las familias indígenas.
- Se cree un sistema de apoyos para iniciativas endógenas de recuperación y revitalización de los idiomas originarios, en áreas rurales y urbanas.
- Sean aplicadas iniciativas gubernamentales en favor de las lenguas indígenas en consulta con las organizaciones indígenas y las comunidades de hablantes.
- Formular e implementar políticas lingüísticas y culturales para y con los pueblos indígenas, también es parte de los objetivos del IIALI, para ello se pretende:
- Que sean fortalecidos técnicamente las Secretarías, institutos o academias oficiales de idiomas originarios y políticas lingüísticas y con actuación en los niveles macro, meso y micro.
- Tener un Laboratorio Latinoamericano de Lenguas Indígenas en funcionamiento, con bases de datos cuantitativos y cualitativos sobre la situación de los idiomas indígenas. (https://www.iiali.org/objetivos-del-iiali/)
Saiba mais puxando. rede IPOL:
. A criação do Instituto: http://ipol.org.br/tag/instituto-ibero-americano-de-linguas-indigenas-iiali/
. A criação do Instituto Ibero-Americano de Línguas Indígenas (IIALI): https://www.segib.org/pt-br/programa/iniciativa-instituto-iberoamericano-de-lenguas-indigenas-iiali/
“Inventário da Língua Pomerana (ILP)” está disponível em formato e-book. Errata
Errata: um novo link para acesso da publicação está disponível na postagem:
“Inventário da Língua Pomerana (ILP)” está disponível em formato e-book.
Comitiva de italianos tem audiência com Eugenia Tiziana Berti, Consul Geral da Itália PR/SC

Consul Eugenia Tiziana Berti (vermelho) juntamente com a comitiva dos estados de SC e PR que participaram do encontro.
15 de novembro 2023 – Ipumirim Notícias
Municípios de cultura Italiana do Oeste tem qualidades que vão além da Língua Italiana e da dupla cidadania.
Uma comitiva de associados da Federação de Entidades Ítalo-brasileiras e de Mestres e Ofícios da Cultura Taliana – FEIBEMO, dos municípios de Concórdia, Ipumirim, Nova Erechim, Pinhalzinho, Formosa do Sul, Maravilha e Caçador, participaram no sábado, em Curitiba, de uma audiência com a Consul Geral da Itália PR/SC, Eugenia Tiziana Berti.
A Consul conheceu um pouco sobre eventos e ações das comunidades italianas de pequenos municípios do oeste catarinense e de suas características históricas e culturais, ganhou de presente pratos típicos da culinária de subsistência dos imigrantes e seus descendentes, produtos coloniais e livros da Língua Talian e surpreendeu a todos pela acessibilidade e vontade de conhecer a realidade que vai além do ensino da Língua Italiana e da Dupla Cidadania.
O grupo esteve sob a coordenação de Nedi Terezinha Locatelli, diretora de patrimônio cultural da FEIBEMO, que ficou encarregada ao final da audiência, de organizar ações de diálogo e aproximação entre o Consulado e a Federação e suas associadas. Além de Nedi, de Ipumirim, participou Gilmar da Rosa, coordenador geral do projeto Salame Colonial Talian do Oeste Catarinense e de Concórdia, Adriana Portolan, Jordão (Pòpo) Zanella e Enio (Nêne) Magro.
Encontro Nacional dos Difusores do Talian
Na noite de sexta-feira dia 10 e sábado, dia 11, a mesma comitiva participou do XXVII Encontro Nacional dos Difusores do Talian, em Colombo – PR, evento anual que trata de questões de interesse da Língua Talian, reconhecida pelo MinC/IPHAN, em 2014, como Língua de Referência Cultural Brasileira.
O radialista de talian Nêne Magro (Enio) do programa Taliani Contenti, da Rádio Aliança de Concórdia, participa dos encontros há mais de 20 anos e declara sua surpresa pela excelente qualidade do encontro de Colombo, tanto pela organização, como pelo conteúdo das palestras e pela beleza da missa celebrada e cantada em Talian. “Uma oportunidade única de convivência. Ao mesmo tempo que tem brincadeiras, tem ricos aprendizados que levamos para nossas ações do Talian e para a vida.”
Um dos assuntos tratados nesse encontro foi a cooficialização de línguas no âmbito municipal, – tramite legal e conceitos culturais -, tema que ficou sob a responsabilidade de Nedi Terezinha Locatelli, coordenadora do Comitê Nacional Gestor da Língua Talian – CONTALIAN.
Saiba mais sobre o evento em Colombo-PR puxando a Rede:
https://www.facebook.com/talianlenguaecultura/?locale=pt_BR


Forlibi – Fórum Permanente das Línguas Brasileiras de Imigração
I Seminário de Gestão em Educação Linguística da Fronteira do MERCOSUL
