
A floresta tem um plano para salvar o planeta da crise climática
Indígenas, Ribeirinhos, Quilombolas e ativistas da Pan-Amazônia fazem um tratado com propostas para barrar o colapso diante do fracasso das negociações das COPs

Arquivo FOSPA
O pequeno barco a motor se aproxima devagar da margem do Rio Beni. É preciso cuidado para colocar os pés na areia e pisar o solo umedecido pelas chuvas recentes. Uma trilha leva, então, ao centro de Carmen Florida, aldeia do povo Takana dentro da Reserva da Biosfera Pilón Lajas, na Amazônia boliviana, onde um enorme gramado verde é rodeado por casas. As nuvens são um alento para uma comunidade que seis meses antes estava cercada por incêndios espalhados pela mata. Naquelas semanas em que o fogo se aproximou, faltaram água e comida. Crianças se intoxicaram com a fumaça. A escola fechou. Agora, o caminho está verde e a roça dá sinais de que revive, mas o plantio ainda sofre porque a seca não recuou completamente. Mais um efeito da crise climática.
O tempo, antes mais previsível, agora é pouco compreendido. Se hoje falta chuva, no passado, por duas vezes, Carmen Florida precisou se reconstruir em áreas mais altas do território por conta das enchentes. O Rio Beni também está mais turvo, descrevem os moradores, contaminado por vestígios de projetos de mineração que ficam a algumas horas dali. Por perto, há máquinas na mata: fantasma de mais um devaneio estatal, a construção de dois megaprojetos hidrelétricos, Chepete e El Bala, que podem deixar diversas vilas – além de toda a história delas – embaixo d’água. Os planos do governo boliviano estão, por ora, paralisados, depois de uma intensa pressão da sociedade, incluindo a de Carmen Florida, mas o Estado não recuou oficialmente e o aparato usado no estudo dos projetos ainda está na floresta e assombra os Indígenas.
Siga a leitura na fonte em Sumaúma, jornalismo do centro do mundo:
https://sumauma.com/a-floresta-tem-um-plano-para-salvar-o-planeta-da-crise-climatica/
Saiba mais puxando a rede IPOL
. Fórum Social Pan-Amazônico –FOSPA
https://www.forosocialpanamazonico.com/
O Fórum Social Pan-Amazônico –FOSPA- é um espaço de articulação, ação e reflexão relacionado à bacia amazônica que atravessa Brasil, Peru, Bolívia, Equador, Colômbia, Venezuela, República Cooperativa da Guiana, Suriname e Guiana (francesa).
. Declaração Pan-Amazônica de Rurrenabaque: XI FOSPA divulga carta final
https://repam.org.br/declaracao-pan-amazonica-de-rurrenabaque-xi-fospa-divulga-carta-final/
Evento reúne 500 indígenas de 18 etnias em Goiás
.
Por Madson Euler – Repórter da Rádio Nacional – São Luís

A edição de número 16 da Aldeia Multiétnica, que encerrou nesse sábado, reuniu representantes e lideranças indígenas do país e de fora, na Chapada dos Veadeiros, em Goiás. Durante oito dias, 500 indígenas de 18 etnias do Brasil, Canadá, Peru e Bolívia, compartilharam danças, cânticos, celebrações, comidas, artesanatos e modos de vida de seus povos.
O evento faz parte da celebração dos 20 anos da Política Nacional Cultura Viva, que certifica e fomenta grupos culturais nos territórios. Foram realizados encontros entre representantes do Ministério da Cultura e lideranças indígenas sobre políticas públicas, como a seleção de 42 Pontões Temáticos e Territoriais, que vão receber investimento de R$ 28 milhões.
Serão desenvolvidos também projetos em áreas como cultura popular e tradicional, matriz africana, patrimônio e memória, literatura, digital, entre outras. As iniciativas selecionadas para serem pontões de cultura vão receber um repasse de R$ 400 mil a R$ 800 mil para a execução de um projeto cultural pelo período de 12 meses. Ao todo, 306 pontos de cultura estarão envolvidos nessa estratégia, considerando que cada pontão tem um comitê gestor.
Saiba mais puxando a rede IPOL
. O que é a Aldeia Multiétnica
É um território na Chapada dos Veadeiros dedicado ao fortalecimento das culturas e lutas políticas dos povos indígenas e quilombolas.
Estamos no coração da Chapada dos Veadeiros, cercados de paisagens impressionantes e muito preservadas de Cerrado, o segundo maior bioma brasileiro.
Siga a leitura no link:
https://www.aldeiamultietnica.com.br/
. Formação de jovens indígenas e articulação do Pontão de Culturas Indígenas marcam 16ª Aldeia Multiétnica

As danças, cânticos, celebrações, comidas, artesanatos e os modos de vida de povos indígenas de todas as regiões do país ocuparam, por oito dias, a 16ª Aldeia Multiétnica, na Chapada dos Veadeiros (GO). O festival, que chega ao fim neste sábado (20), também foi palco do 1º Circuito de Culturas Indígenas, com a presença de representantes do Ministério da Cultura (MinC) para dialogar com as lideranças indígenas sobre o acesso aos recursos federais e às políticas públicas culturais, nos dias 18 e 19 de julho. O evento integrou a programação de celebração aos 20 anos da Política Nacional Cultura Viva (PNCV), que certifica e fomenta grupos cultuais nos territórios. Hoje já são quase seis mil pontos e pontões de cultura no Cadastro Nacional.
Siga a leitura no link: https://agenciagov.ebc.com.br/noticias/202407/formacao-de-jovens-indigenas-e-articulacao-do-pontao-de-culturas-indigenas-marcam-16a-aldeia-multietnica
Cimi registra ataques a povos indígenas em três estados
.
Indigenistas dizem que são ações em contextos similares

Foto Eloy Terena
Publicado por Agência Brasil em 20/07/24
Os conflitos entre produtores rurais e grupos indígenas continuam no Mato Grosso do Sul e Paraná. De acordo com publicação feita neste sábado (20) pelo Conselho Indigenista Missionário (Cimi), com base em informações da Comissão Guarani Yvyrupa, foram registrados cerco a indígenas guarani kaiowá em retomadas de área no Mato Grosso do Sul, com risco iminente de despejo ilegal e forçado, e incêndio criminoso contra o tekoha Tata Rendy, dos ava guarani, no oeste do Paraná. O Cimi registou ainda neste sábado ataques a indígenas no Rio Grande do Sul. 

De acordo com o Cimi, no Mato Grosso do Sul, as cinco retomadas da região de Douradina circunscritas à Terra Indígena Lagoa Rica Panambi continuam sendo acossadas por capangas armados desde a manhã deste sábado. Em campo aberto, quase uma dezena de caminhonetes se posicionaram com homens nas caçambas, que rapidamente se espalharam em um perímetro ofensivo ao grupo guarani kaiowá. A Força Nacional de Segurança está no local.
Em Caarapó (MS), na manhã deste sábado, duas áreas retomadas na Terra Indígena Dourados Amambai Peguá I passaram a ser sobrevoadas por drones e cercadas por caminhonetes.
No oeste do Paraná, na tekoha – termo usado para definir território – Tata Rendy, dos ava guarani, também houve cerco e incêndios. Para indígenas e indigenistas, tratam-se de ataques em bloco dentro de contextos similares.
Além desses conflitos, o Cimi, órgão vinculado à Conferência Nacional dos Bispos do Brasil (CNBB), registrou ainda ataques ao povo kaingang da Retomada Fág Nor, em Pontão, localizado próximo ao município de Passo Fundo, no Rio Grande do Sul. Os indígenas voltaram a ser atacados na madrugada deste sábado (20). Homens encapuzados desceram de veículos e atiraram contra os indígenas e incendiaram uma maloca. Em uma semana, é o terceiro ataque sofrido depois que as famílias decidiram retornar para uma área próxima ao território tradicional.
Governo federal
Os conflitos se estendem por cerca de uma semana. No último dia 16, representantes do governo federal deixaram Brasília e desembarcaram em Mato Grosso do Sul. O objetivo das equipes dos ministérios dos Povos Indígenas (MPI) e dos Direitos Humanos e da Cidadania (MDHC) é “mediar conflitos fundiários” que culminaram em uma série de ataques contra indígenas que ocuparam áreas rurais reivindicadas como territórios tradicionais.
No dia 17, o Ministério da Justiça e Segurança Pública autorizou o emprego de agentes da Força Nacional em ações estatais para preservar a ordem e a integridade em aldeias indígenas do Cone Sul do Mato Grosso do Sul e nas regiões fronteiriças do estado.
Segundo o Cimi, apesar das comitivas do Ministério dos Povos Indígenas (MPI), e das tentativas de negociação com proprietários rurais e políticos locais para a interrupção das hostilidades, não houve ainda a presença de um aparato mais sólido do Estado em busca de soluções reais – e até mesmo a ida às regiões de autoridades públicas com peso político. O órgão critica a atuação da Força Nacional.
Ocorre que nos três casos, ava guarani, guarani kaiowá e kaingang, houve incêndio criminoso nas áreas ocupadas pelos indígenas. Os agressores atearam fogo em malocas e nas matas do entorno. Outro ponto em comum é que nos três casos os ataques ocorreram horas após a saída de representantes do Ministério dos Povos Indígenas das áreas e com a presença de agrupamentos da Força Nacional deslocados pelo governo federal às regiões.
Leia a matéria na Fonte:
Saiba mais puxando a rede IPOL:
. Comitiva do governo federal visita áreas de conflitos indígenas no Mato Grosso do Sul
.
Nota de esclarecimento: Falamos e escrevemos o Hunsrückisch!
NOTA DE ESCLARECIMENTO (uff Hunsrückisch)
![]()
Mea spreche unn schreiwe Hunsrückisch!
Weche Notícias, wo die Wuch publikeert gebb sinn, iwer en “Hunsrik” Sproch im Google Tradutor, finne mea uns als Pesquisadore unn Sprecher vom “Hunsrückische”, wie mea unser Sproch nenne, gezwung unser Sorche unn Erstaune iwer die Schrift unn der Oot, wie das Ganze gemacht gebb is, zum Ausdruck ze bringe. Was uns noch traurich macht, is, dass debei importante Pesquisas ignoreert gebb sinn, wo der Inventário Nacional von der Sprochdiversitet dorich der IPHAN (Instituto do Patrimônio Histórico e Artístico Nacional) ons Licht gebrung hot ( https://www.gov.br/iphan/pt-br/assuntos/noticias/mais-6-linguas-podem-se-tornar-referencia-cultural-brasileira )
In dem Sinn muss ma soohn, vor allem, dass die Schrift, wo der Google Tradutor verwendt, uff kee Fall unser Schrift vom Hunsrückische representeert, wo dorich der Inventário festgesetzt unn legitimeert gebb is, in en Inventário wo der IPOL (Instituto de Investigação e Desenvolvimento em Política Linguística) unn das Projekt ALMA-H (Sprochkontaktatlas von der Deitsche Minorias in der Bacia do Prata: Hunsrückisch) on der Universidade Federal do Rio Grande do Sul (UFRGS) von 2016 bis 2018 gemacht gebb is (meh dezu unner https://www.ufrgs.br/projalma/escrithu-sistema-de-escrita-do-hunsruckisch/).
Die Schrift, wo ohne Kriterie aleatorisch unner dem Noome Hunsrik verwendt wedd, is en fonetisch Schrift; das Wott “alemão” wedd somit als Taytx geschribb. Im Gecheteel die Schrift, wo dorich der Inventário vom Hunsrückische aproveert gebb is, heert der Tradition unn dem Schreiwe von Imigrante unn dene sein Nohkommenschaft iwer die 200 Johre in Brasilie (in dem Johr mit en Heerd Atividades gedenkt); das Wott for “alemão” schreibt ma uff der Oot als Deitsch. Der Diálogo mit der Herkunft unn mit der eichne Identitet is ausserondlich central for die Sprecher vom Hunsrückische, well dodemit erlaubt wedd, ooch annre Atikle von unser Kultur mitzerechne, wie, for em Beispiel ze gewwe, die Verschriftung von Schreibnoome zeicht (em Beispiel is das ooch in viele Noome wie Schneider, Einstein unn so weiter). Das heesst, das Festsetze von der Schrift im Inventário hot sich aus dem Diálogo mit der Sprecher unn ehr Geschicht ergebb, also net vom Ausland renn, wie die Schrift, wo im Google Tradutor verwendt wedd.
Der Oot, wie so das Hunsrik im Google Tradutor uffgenomm gebb is, ohne der Inventário vom Hunsrückische iwerhaupt ze erkenne, ohne die Sprecher unn Gemeende onzeheere unn ohne die Oorwet vom IPHAN mit der Parceria von der Gesellschaft for die bresilioonisch Sprochediversitet ze erkenne unn erhalle, stosst also derekt geche alles, was mit gross Mih gemacht gebb is, for das Hunsrückische ze erhalle unn ze schitze.
Ma muss noch soohn, dass der Inventário vom Hunsrückische, zu dem en Parecer Técnico im Diário Oficial da União vom 05.07.2022, ed. 125, seção 3, p. 127 rausgebb is, en importante Beweis is, for das Hunsrückische der Certificado als “referência cultural brasileira” ze kriehn. Das is uns vom IPHAN noch eenmol besteticht gebb, in en Reunião vom 12.07.2024. Debei is uns ooch gesichert gebb, dass der Certificado noch das Johr ausgestellt werre kann.
Mea hoffe zum Schluss, dass hiermit besser verstann wedd, wie ennst die Stuation is. Es hannelt sich um die Mottersproch von en Heerd Leit unn ehr Geschicht, wo net eenfach von en eenzich Aktion decidiert werre kann. Es solte die Interesse von der Sprecher zehle, well for die Hunsrückisch en Erebsproch is. Ma muss dem Google desweche vorschloohn, das Insetze von neie Sproche im Google Tradutor besser ze kontroleere, unn die Sicht von der viele Sprecher sowie ooch die Politik vom Inventário Nacional von der Sprochdiversitet ennst ze nehme, wo en important Institution wie der IPHAN unnerstizt hot, uff der Basis grood von ennst Dokumentation unn Zustimmung von der Sprecher.
Es danke for das Zuheere
Cléo V. Altenhofen (Projeto ALMA-H / UFRGS, Instituto de Letras)
Rosângela Morello (IPOL – Instituto de Investigação e Desenvolvimento em Política Linguística)
.
NOTA DE ESCLARECIMENTO:
Falamos e escrevemos o Hunsrückisch!
Em virtude de notícias que têm sido veiculadas nesta semana, referindo-se à inclusão de uma língua Hunsrik, no Google Tradutor, viemos manifestar nossa surpresa e preocupação, como pesquisadores e falantes do Hunsrückisch, com o sistema de escrita usado e o modo como se deu esse processo de inclusão, ignorando trabalhos relevantes no âmbito do Inventário Nacional da Diversidade Linguística (https://www.gov.br/iphan/pt-br/assuntos/noticias/mais-6-linguas-podem-se-tornar-referencia-cultural-brasileira), conforme concebido pelo IPHAN (Instituto do Patrimônio Histórico e Artístico Nacional).
Nesse sentido, cabe esclarecer, antes de tudo, que a escrita usada no Google Tradutor não representa de modo algum a escrita definida e legitimada como escrita usual do Hunsrückisch, por meio do Inventário que o IPOL (Instituto de Investigação e Desenvolvimento em Política Linguística) e o projeto ALMA-H (Atlas Linguístico-Contatual das Minorias Alemãs na Bacia do Prata: Hunsrückisch), da Universidade Federal do Rio Grande do Sul (UFRGS), realizaram entre 2016 e 2018 (v. https://www.ufrgs.br/projalma/escrithu-sistema-de-escrita-do-hunsruckisch/)
A escrita usada nessa inclusão aleatória do que se chama Hunsrik é fonética; por exemplo, para a palavra ‘alemão’, escreve-se a forma Taytx. Em contrapartida, a escrita aprovada no Inventário do Hunsrückisch dialoga com a tradição e as práticas de escrita dos imigrantes e seus descendentes ao longo dos 200 anos de presença no Brasil (rememorados em uma série de atividades deste ano de 2024); a palavra equivalente a ‘alemão’ é escrita, por isso, como Deitsch. Esse diálogo com as raízes e a identidade local é central para os falantes de Hunsrückisch, pois possibilita alinhar as práticas de escrita com outros setores da cultura, como por exemplo mostra a grafia de sobrenomes (neste caso, com o mesmo grafema em Schneider, Einstein etc.). Ou seja, a definição do sistema de escrita, no âmbito do Inventário, deu-se em diálogo com as comunidades, e não foi artificialmente introduzido de fora para dentro, como no caso da escrita do Google Tradutor.
A inserção, de forma aleatória, da língua Hunsrik no Google Tradutor, sem consideração do Inventário do Hunsrückisch, em que se fez ampla consulta e pesquisa junto às comunidades de falantes, e que representa um esforço do IPHAN, junto com a sociedade, para reconhecer e salvaguardar a diversidade linguística brasileira, se choca, portanto, com os esforços legitimamente empreendidos para a manutenção e salvaguarda do Hunsrückisch.
Vale acrescentar que o Inventário do Hunsrückisch, com parecer técnico publicado no DOU de 05/07/2022, ed. 125, seção 3, p. 127, é requisito essencial para o Hunsrückisch obter o certificado de “referência cultural brasileira”. Essa postura foi corroborada em reunião realizada com o IPHAN, no último dia 12/07/2024, em que se acenou com a concessão do certificado ainda este ano.
Esperamos, enfim, que esta nota esclareça a situação, pois a língua materna de toda uma comunidade e de sua história não pode ficar à mercê de uma decisão isolada, motivada por interesses que não os dos falantes, para quem o Hunsrückisch constitui uma língua de herança. Caberia, por isso, alertar ao Google, para rever o processo de inclusão de línguas no Google Tradutor, sem ferir ou passar por cima da visão das comunidades de falantes e da política do Inventário Nacional da Diversidade Linguística, conduzida por um órgão extremamente importante como o IPHAN, que ampara suas ações justamente na documentação e anuência das comunidades.
Att.
Cléo V. Altenhofen (Projeto ALMA-H / UFRGS, Instituto de Letras)
Rosângela Morello (IPOL – Instituto de Investigação e Desenvolvimento em Política Linguística)
DISCLAIMER:
We speak and write Hunsrückisch!
As a result of the news that has been published this week, referring to the inclusion of a Hunsrik language in Google Translate, we would like to express our surprise and concern, as researchers and speakers of Hunsrückisch, about the writing system used and how this process of inclusion has taken place, ignoring relevant work within the scope of the National Inventory of Linguistic Diversity (https://www.gov.br/iphan/pt-br/assuntos/noticias/mais6-linguas-podem-se-tornar-referencia-cultural-brasileira), as conceived by IPHAN (Institute of National Historical and Artistic Heritage).
First and foremost, it should be clarified that the writing used in Google Translate in no way represents the writing defined and legitimized as the usual writing of Hunsrückisch, through the Inventory that IPOL (Institute for Research and Development in Linguistic Policy) and the ALMA-H project (Linguistic-Contact Atlas of German Minorities in the River Plate Basin: Hunsrückisch), of the Federal University of Rio Grande do Sul (UFRGS), carried out between 2016 and 2018 (see https://www.ufrgs.br/projalma/escrithu-sistema-de-escrita-do-hunsruckisch/).
The writing used in this random inclusion of what is called Hunsrik is phonetic; for example, for the word ‘German’, the form Taytx is written. On the other hand, the writing approved in the Hunsrückisch Inventory dialogues with the tradition and writing practices of immigrants and their descendants over the 200 years of their presence in Brazil (commemorated in a series of activities in 2024); the word equivalent to ‘German’ is therefore written as Deitsch. This dialogue with roots and local identity is central to Hunsrückisch speakers, as it makes it possible to align writing practices with other sectors of culture, as, for example, the spelling of surnames shows (in this case, with the same spelling <ei> in Schneider, Einstein, etc.). The definition of the writing system, in the context of the Inventory, took place in dialogue with the communities and was not artificially introduced from outside, as in the case of the Hunsrik writing now present in Google Translate.
The random inclusion of the Hunsrik language in Google Translate, without taking into account the Hunsrückisch Inventory, in which there was extensive consultation and research with the communities of speakers, and which represents an effort by IPHAN, together with society, to recognize and safeguard Brazilian linguistic diversity, therefore clashes with the efforts legitimately undertaken to maintain and protect this language.
Furthermore, the Hunsrückisch Inventory, with a technical opinion published in the DOU of 05/07/2022, ed. 125, section 3, p. 127, is an essential requirement for Hunsrückisch to obtain the certificate of “Brazilian cultural reference”. This stance was corroborated at a meeting held with IPHAN on July 12, 2024, in which the certificate was expected to be granted this year.
Finally, we can only hope that this disclaimer clarifies the situation since the mother tongue of an entire community and its history cannot be at the mercy of an isolated decision, motivated by interests other than those of the speakers, for whom Hunsrückisch is a heritage language. It would therefore be appropriate to alert Google to review the process of including languages in Google Translate, without hurting or bypassing the vision of the communities of speakers and the policy of the National Inventory of Linguistic Diversity, conducted by a body as important as IPHAN, which bases its actions precisely on the documentation and consent of the communities.
Sincerely,
Cléo V. Altenhofen (Projeto ALMA-H / UFRGS, Instituto de Letras)
Rosângela Morello (IPOL – Instituto de Investigação e Desenvolvimento em Política Linguística)
Monitoramento aponta falta de adaptação linguística para indígenas nas eleições
16 de julho de 2024
Isabella Rabelo – Da Cenarium*
MANAUS (AM) – Em monitoramento realizado pelo Ministério Público do Amazonas (MP-AM), foi destacada a ausência de adaptação linguística em seções eleitorais no Amazonas. A iniciativa, realizada por meio da 50ª Zona Eleitoral do município de Juruá (AM), distante 674 quilômetros de Manaus, visa promover a inclusão das populações tradicionais, especialmente os povos indígenas, no processo eleitoral de 2024.
De acordo com o MP-AM, a problemática foi levantada porque a falta do procedimento impede que indígenas compreendam completamente o processo eleitoral, incluindo aspectos básicos como os horários de votação no dia da eleição. Essa barreira linguística pode criar um ambiente propício para golpes e disseminação de desinformação, comprometendo a integridade da eleição.
Visando assegurar que os direitos políticos das populações tradicionais sejam respeitados e garantidos de forma igualitária, a portaria de instauração do procedimento foi assinada pelo promotor eleitoral Rafael Augusto del Castillo da Fonseca, que destacou a importância de garantir que todos os cidadãos, independentemente de sua origem, tenham o pleno direito ao sufrágio universal.

“Essa ação está alinhada com as diretrizes do calendário eleitoral, e garante que indígenas, ribeirinhos, comunitários e outros grupos da zona eleitoral de Juruá tenham todas as condições necessárias para exercer seu direito ao voto como cidadãos brasileiros”, enfatizou.
Reconhecimento
Para a presidente da Comissão dos Povos Indígenas da Ordem dos Advogados do Brasil Seccional Amazonas (OAB-AM), advogada Inory Kanamari, a ação demonstra que o sistema de Justiça brasileiro, está reconhecendo existência da população indígena como parte do país.
“Durante a história sempre fomos obrigados a nos adaptar aos costumes dos invasores, e isso sempre foi normalizado pelo Estado. Esperamos que essa atuação do MP-AM respeite a diversidade cultural e linguística, bem como se atente as especificidades de cada povo”, enfatizou a advogada.
“É importante ressaltar que o Amazonas é o estado brasileiro mais indígena do país, segundo o último senso do IBGE, e mesmo assim seguimos sendo muitas vezes invisibilizados e infelizmente lembrados apenas em períodos eleitorais”, observou.

Legislação
A Constituição Brasileira garante no artigo 231 o direito dos povos indígenas a utilização das suas línguas em diversos processos, desde o pleito eleitoral até a educação de ensino básico, respeitando seus próprios processos de aprendizagem.
“São reconhecidos aos índios sua organização social, costumes, línguas, crenças e tradições, e os direitos originários sobre as terras que tradicionalmente ocupam, competindo à União demarcá-las, proteger e fazer respeitar todos os seus bens”, diz parte do texto do artigo 231.
Publicado em Revista Cenarium : https://revistacenarium.com.br/monitoramento-aponta-falta-de-adaptacao-linguistica-para-indigenas-nas-eleicoes/
O INGLÊS COMO FORMA DE COLONIALIDADE DO SABER NA CIÊNCIA
Por Robson Fernandes e Marcia Alvim
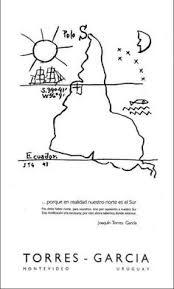
América Invertida é um desenho de caneta e tinta de 1943 do artista hispano-uruguaio Joaquín Torres García.
Inúmeros fatores históricos e geopolíticos corroboraram para a utilização da língua inglesa em escala global. No que se refere a produção científica, o inglês é considerado a língua franca das ciências, permitindo que pesquisadores de várias nações compartilhem informações usando um idioma comum. O crescimento constante no número de artigos científicos publicados em inglês demonstra sua ampla adoção por pesquisadores, cientistas, periódicos e repositórios, incluindo aqueles de países que não falam inglês como língua materna. Este processo também abrange propostas de internacionalização das instituições de pesquisa e ensino, bem como a avaliação de pesquisadores e rankings acadêmicos.
Durante o século XX, com o fortalecimento econômico dos Estados Unidos da América, especialmente após a Segunda Guerra Mundial, a língua inglesa foi amplamente difundida ao redor do mundo, tornando-se a principal forma de contato entre as nações. Faz-se relevante discutirmos a relação entre linguagem, ciência e geopolítica e como estes âmbitos são capazes de refletir e de perpetuar estruturas de poder coloniais impostas hierarquicamente, as quais contribuem para a sustentação de diferentes formas de colonialidade, agora não apenas territoriais, mas também linguísticas, científicas e culturais.
O uso predominante do inglês como língua franca da ciência pode ser interpretado à luz da teoria decolonial como uma manifestação da colonialidade do saber. Autores como Aníbal Quijano, Maldonado Torres, Walter Mignolo e Catherine Wash ressaltam que a determinação do inglês como língua franca gera uma hierarquia linguística capaz de marginalizar outras línguas e formas de conhecimento, reforçando sistemas de poder coloniais, especialmente frente ao que denominaremos como monolinguismo.
O monolinguismo do inglês como idioma acadêmico-científico chega a passar de forma quase despercebida, visto que é utilizado como padrão em diversos meios de produção e circulação científica, tais como, publicações, palestras e eventos, além do amplo número de publicações, causando uma espécie de imperialismo linguístico, fenômeno considerado como manifestação da colonialidade do saber, conforme aponta Mignolo:
Uma hierarquia linguística, entre as línguas europeias e as línguas não europeias, privilegiava a comunicação e a produção do conhecimento teórico nas línguas europeias e subalternizava as línguas não europeias como apenas produtoras de folclore ou cultura, mas não de conhecimento/ teoria (Mignolo, 2005, p. 18).
No processo de imposição colonial, as línguas dos colonizadores tornaram-se línguas oficiais de países colonizados e as lutas pelas independências em relação ao colonialismo não significou o fim das diferentes formas de dominação. Anibal Quijano (2005) denomina de colonialidade do poder a matriz colonial de poder que mantém ingerência em diferentes aspectos da vida social e cultural dos países que vivenciaram a colonização.
No contexto de colonialidade do poder e do saber, Mignolo aponta para a necessidade de reflexão sobre este padrão epistemológico da razão universal, buscando romper com o processo de colonização epistemológica presente, inclusive, na indicação da língua padrão da ciência: “[…] os corpos inferiores carregavam inteligência e línguas inferiores” (Mignolo, 2005, p.143).
Neste sentido, a legitimação do uso monolíngue do inglês como meio de comunicação privilegia epistemologias ocidentais dominantes em detrimento de saberes locais e indígenas, perpetuando a lógica da colonialidade, da dominação e da subalternização. Assim, o uso prioritário do inglês na esfera acadêmica-científica pode ser visto como uma forma neocolonial, já que está totalmente alinhado aos interesses dos países do norte global. Esta hegemonia reforça a assimetria na divulgação dos resultados das pesquisas e das produções científicas, tanto na recepção quanto na circulação das produções acadêmicas, desconsiderando as dificuldades que esses mesmos pesquisadores enfrentam para produzir e, também, para terem seus textos aceitos para publicação em periódicos de prestígio.
O uso do inglês como língua comum na comunicação universitária também está presente nas instituições de ensino superior (IES) que buscam se internacionalizar o que demonstra que o fazer científico-acadêmico permanece atrelado aos padrões eurocêntricos ou nortecentrados, dando continuidade à representação da colonialidade do saber nos países periféricos.
Além da manutenção da colonialidade pelo uso da língua hegemônica, pode-se observar um processo de inferiorização imposto aos países emergentes, os quais devem seguir os modelos nortecêntricos como padrões científicos e culturais, evidenciando-se as diversas formas de apagamento de conhecimentos oriundos de povos silenciados, dado que o conhecimento científico produzido, reproduzido, referenciado e compartilhado atualmente pelas instituições universitárias necessariamente se faz por meio de uma língua estrangeira comum, o inglês, estabelecendo-se, portanto, uma forma de colonialidade do saber nas ciências, dada a tentativa de universalização do conhecimento por meio de uma língua hegemônica.
Deste modo, é de suma importância a problematização da hegemonia da língua inglesa nas ciências e, conforme Hamel (2007), pensar outras possibilidades linguísticas para a produção de conhecimentos, como o multilinguismo e o plurilinguismo. Estes surgem como alternativas ao monolinguismo na produção científica, possibilitando novas formas de comunicação entre a comunidade científica, capazes de mitigar a exclusividade da língua inglesa nas produções científico-acadêmicas.
O multilinguismo, termo que se refere à possiblidade de coexistência de sistemas linguísticos diferentes (língua, dialeto, fala) dentro de uma comunidade seria um mecanismo estratégico, mediante ao monolinguismo atual, e poderia ser utilizado para representar a diversidade linguística presente na América do Sul, buscando-se uma integração entre o espanhol, o português e o inglês, e, certamente, a influência de línguas de comunidades originárias existentes nestas localidades, visto que a redução da diversidade linguística pode impactar na diversidade cultural das nações.
Oconceito de plurilinguismo refere-se à presença e à interação de várias línguas dentro de uma comunidade específica, superando multilinguismo. Hamel (2007) destaca a importância de políticas linguísticas que promovam a equidade e a inclusão social, reconhecendo o valor das línguas indígenas minoritárias, essenciais para a preservação da diversidade cultural. Amon (2001) reforça as possíveis implicações desse conceito no âmbito educacional e profissional, destacando a necessidade de desenvolver competências plurilíngues para uma melhor integração e comunicação em sociedades globalizadas.
Devido às diversas barreiras linguísticas enfrentadas por pesquisadores no processo de produção científica, autores como Enrique Hamel (2007), Hans De Wit (2016), Gilvan Oliveira (2017) e Ulrich Amon (2001) têm discutido a implementação de uma Política e Planejamento Linguístico na Ciência e na Educação Superior (PPLICES), visando uma educação mais abrangente e inclusiva em termos linguísticos.
Neste contexto, consideramos fundamental a problematização da utilização prioritária da língua inglesa pela comunidade científica, a qual não deve ser tratada apenas como uma ferramenta capaz de atender aos padrões dos países do norte global, mas, sobretudo, como forma de romper com a imposição à determinadas demandas epistemológicas e acadêmicas constituídas pela colonialidade do saber. Deste modo, a proposição da criação de uma Política de Planejamento Linguístico na Ciência e na Educação Superior (PPLICES), as quais buscassem integrar os países periféricos aos diversos centros de pesquisa de todo o mundo, mas não apenas de modo hierárquico e subalterno aos países do norte global. Por meio de uma nova proposta multilíngue seria possível a constituição de redes de pesquisa integradas à perspectiva sul-sul global, capazes de tratarem o processo de comunicação científica de maneira horizontal, de acordo com os diferentes contextos e culturas.
Portanto, concluímos que, embora o inglês possa ser uma ferramenta útil na ciência, é crucial que ele não seja a única forma reconhecida e valorizada pela comunidade científica, mas sim um meio de facilitar a comunicação. Devemos refletir sobre alterativas decoloniais que possam promover a diversidade linguística por meio de políticas e ações que incentivem o multilinguismo e o plurilinguismo, pois consideramos que tais recursos permitem o uso de diversas línguas e tradições de conhecimentos, capazes de valorizar a diversidade linguística (e cultural) que enriquece a experiência educacional, cultural, acadêmica e científica, contribuindo para uma ciência mais inclusiva, anticolonial e alinhada aos princípios de justiça cognitiva e equidade global.
Robson Fernandes é mestre em Ensino e História das Ciências e da Matemática pela UFABC, Especialista em Língua Inglesa pela UMESP e Graduado em Letras (Português /Inglês) pelo Centro Universitário da Fundação Santo André.
Marcia Alvim é doutora em Ciências – Ensino e História da Ciência e mestra em Ensino e História das Ciências da Terra (IG/Unicamp), graduada em História (IFCH/Unicamp) e docente associada do Centro de Ciências Naturais e Humanas da UFABC.
Referencias bibliográficas
AMON, Ulrich. The dominance of English as a language of science: effects on other languages and language communities. Berlin, New York: De Gruyter Mouton, 2001, 471 p.
DE WIT, Hans; HUNTER, Fiona.; HOWARD, Laura; EGRON-POLACK, Eva. The internationalisation of higher education. Brussels: European Parliament, Committee on Culture and Education, 2015. Disponível em: https://www.europarl.europa.eu/RegData/etudes/STUD/2015/540370/IPOL_STU(2015)540370_EN.pdf. Acesso em: 22 jul. 2022.
HAMEL, Enrique R. The dominance of English in the international scientific periodical literature and the future of language use in science. AILA Review, [S.I.], v. 20, n. 1, p. 53-71, 2007. DOI: 10.1075/aila.20.06ham. Disponível em: https://www.jbe-platform.com/content/journals/10.1075/aila.20.06ham. Acesso em: 02 abr. 22.
MIGNOLO, Walter D. A colonialidade de cabo a rabo: O hemisfério ocidental no horizonte conceitual da modernidade. In: LANDER, Edgardo (Org). A colonialidade do saber: Eurocentrismo e ciências sociais. Buenos Aires: Perspectivas latino-americanas, 2005. cap 3. p. 35-54. Disponível em: https://biblioteca-repositorio.clacso.edu.ar/bitstream/CLACSO/14084/1/colonialidade.pdf. Acesso em: 20 jul. 2021.
OLIVEIRA, Gilvan. Política linguística e internacionalização: a língua portuguesa no mundo globalizado do século XXI. Trabalhos em Linguística Aplicada, Campinas , v. 52, n. 2, p. 409-433, Dec. 2013. Disponível em: <http://www.scielo.br/scielo.php?script=sci_arttext&pid=S0103-18132013000200010&lng=en&nrm=iso>. Acesso em: 01 nov. 2023.
QUIJANO, Anibal. Colonialidade do poder, eurocentrismo e América Latina. In: QUIJANO, Anibal. A colonialidade do saber: eurocentrismo e ciências sociais, perspectivas latino-americanas. Buenos Aires: CLACSO, 2005.
ARTIGO, _DOSSIÊ 254 publicado em ComCiência , revista digital do Laboratório de Estudos Avançados em Jornalismo (Labjor) da Unicamp em parceria com a Sociedade Brasileira para o Progresso da Ciência (SBPC) , siga o link para a matéria na revista: https://www.comciencia.br/o-ingles-como-forma-de-colonialidade-do-saber-na-ciencia/, ou visite o sumário do dossiê Colonialismo na Ciência publicado em 15/07/2024 em: https://www.comciencia.br/
. Visite a página ComCiência para acessar inúmeros conteúdo e dossiês.
. Visite o portal da SBPC: https://portal.sbpcnet.org.br/
. Acompanhe o canal YouTube SBPCnet com a 76ª Reunião Anual da SBPC
https://www.youtube.com/results?search_query=76%C2%AA+Reuni%C3%A3o+Anual+da+SBPC


Forlibi – Fórum Permanente das Línguas Brasileiras de Imigração
I Seminário de Gestão em Educação Linguística da Fronteira do MERCOSUL
